Administrating a Kubernetes cluster (on bare metal!)
On 10 December 2020 I starter porting all of my (public) server workloads to Kubernetes, on 8 February of 2021, it got merged into production. Today, that same setup is still powering my servers, and you are currently reading a website that is served using that setup. Today, 4.5 years, and many changes later, I am describing my setup and experience with managing a Kubernetes cluster on bare metal.
Docker-Swarm
Before Kubernetes became the backbone of my server, it was running a custom setup based on docker-swarm. The setup worked flawlessly, and I highly recommend a similar setup to admins who want a simple server setup. In a diagram, it would look as follows:
It consists of a simple docker-swarm cluster with a shared glusterfs storage pool. When working with clusters, storage is one of the most difficult parts. Because you should not know which node will run your workload, each node must be able to use any storage volume. A common solution is often to use a dedicated storage NAS (outside of the cluster) from which each node mounts the volumes that it requires. However, this is a setup I wanted to avoid for several reasons:
- It required additional, dedicated, storage hardware
- It would increase the storage latency massively
- My cluster already contains storage, I want to use it
Another difficult part of clusters is loadbalancing, the incoming traffic needs to be routed somewhere, and the workloads must also happen to run there. One solution is to make each node run identical workloads, and then use round-robin to distribute the workload. While that primitive solution might work for some dedicated (single-app) workloads, it would be a nightmare for the storage, as all applications are suddenly required to handle multiple instances. Another solution is to use a single ‘master’ node which receives all traffic, and redirects it internally (adding an additional hop). Docker-swarm uses the latter solution, which is called Layer 4 loadbalancing. Layer 4 loadbalancing works fine, but it is not ideal. In an ideal world, the router already knows which application is run on which node, this would enable layer2 loadbalancing (which would not add any additional hops!).
I said before that the docker-swarm setup works great, and it did. However, it was slightly limited in some ways;
- It requires that all workloads are docker container.
- It did not allow us to specify custom network configurations (without hacky or complex solutions).
- It did not allow for integrated storage solutions, which requires a seperate solution.
- It did not support anything other than layer 4 loadbalancing.
- It did not support role based access control, any user had full access
While docker-swarm is highly opinionated, and comes batteries includes, with many generic solutions out-of-the-box; it is also limited by these solutions. Kubernetes is the exact opposite, it is very open, and comes with no batteries, or even a battery holder, just some extremely well documented wires. Kubernetes allows the admin to configure anything exactly to their wishes, but is also requires admins to configure nearly everything. On managed Kubernetes solutions such as Azure, Digital ocean or GCE; many of these ‘gaps’ are pre-configured, which makes bare-metal second-tier citizens.
If you are interested in replicating my docker-swarm setup, feel free to send me a message. I have detailed setup documentation and many examples available in my internal documentation.
Kubernetes
When Kubernetes became the backbone of my sever, I just spend multiple months playing with it in virtual machines, and experimental bare-metal setups. The world of Kubernetes is complex, and highly specialised. If you are not well-known with Kubernetes terminology, it is a given that you will get lost while attempting to fight the dragon.


Distributions
Kubernetes comes in many ‘distributions’, and I am not talking about dedicated linux distributions that specialise in Kubernetes. They also exist, but I am talking about different Kubernetes distributions. Examples of Kubernetes distributions are:
and many, many, more. As you can see from the list above, its a mess. And most of these can be installed on top of many linux distributions. Your possibilities are endless ;) When I tried to setup my Kubernetes cluster, I spend many days trying and comparing many of these k8s distributions. Some of these, like KubeADM, are very complex to setup and require a lot of knowledge about Kubernetes to setup. In the end I settled on the (now deprecated) K3os, because it offered me the best of both worlds:
- A very easy setup with automatic features such as certificate renewal
- An immutable filesystem (which requires all configuration to be stored in git)
- Batteries included features with the ability to manually configure them
- A lightweight k8s base which does not require many system resources
Replacing some of K3S’s batteries
As I said before, K3S comes with many batteries included, which allows us to stop worrying about Kubernetes’s background setup, and just lets us use the Kubernetes system, as if we were using a managed cloud version. However, because these batteries can’t make many assumptions about my environment, they are not the best. My reasons for using Kubernetes included layer 2 loadbalancing, and using integrated cluster storage. By default k3s uses layer 4 loadbalancing, and ‘local path’ storage which does not work in multi-node setups because it simply stores all volumes on the node that a workload happens to run on. That is where other components come in to fill the gaps
Longhorn
As mentioned before, k3s by default uses a local-path-provisioner, which stores all volumes on the local disk of a node. This is a problem because other nodes do not have access to the local disk. Longhorn is a solution which runs in the cluster, uses in-cluster storage and allows for multi-node setups. It also has many convenient features such as automatic replication, automatic backups and snapshots. Ofcourse, longhorn is not the only supplier for k8s storage. Another common storage solution for Kubernetes is ceph. Ceph is complex and very complicated. Managing Ceph by yourself is guaranteed to take a few years off your life. That is why ‘simplified’ setups like Rook exist. When I was experimenting with my Kubernetes setup, I could not get Rook to work. Longhorn worked out of the box, so I stuck with it.
Creating a PVC (PersistentVolumeClaim) in Kubernetes is automatically picked up by Longhorn, which creates a replicated volume with automatic backup/snapshot schedule. A PVC definition looks as follows:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: gitlab-data-claim
namespace: gitlab
spec:
storageClassName: longhorn-retain
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100GiIn Longhorn, this volume looks as follows:
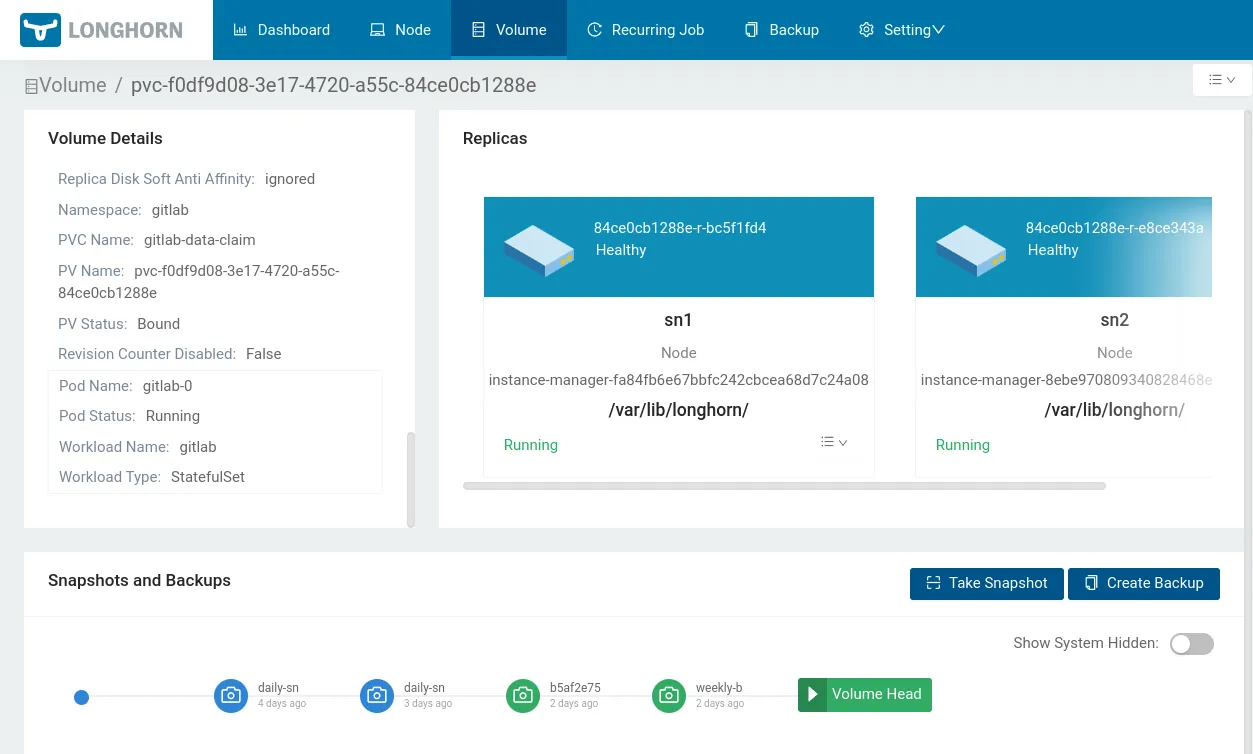
MetalLB
With Longhorn installed, our cluster supports in-cluster storage with all features that you might expect. Another feature that our cluster is missing, is layer2 loadbalancing. By default K3s uses layer4 loadbalancing through Traefik. This requires all traffic to be routed to a single node, which then hops to other nodes if required. In order to do Layer2 loadbalancing, the network infrastructure is required to know which nodes run which workloads. By default, a router does not know this. Cloud providers of Kubernetes have dedicated hardware and custom kubernetes distributions to handle loadbalancing. If you were to install K3s, an declare a loadbalancer as follows:
apiVersion: v1
kind: Service
metadata:
name: minecraft-game
namespace: minecraft
spec:
type: LoadBalancer
externalTrafficPolicy: Local
ports:
- protocol: TCP
name: game-server
port: 25565
selector:
app: minecraftYour loadbalancer will never be created, as Kubernetes does not know how to create your loadbalancer. It will be eternally stuck on Pending. That is there MetalLB steps in. The description of MetalLB does a great job of explaining its reason for existing:
Kubernetes does not offer an implementation of network load balancers (Services of type LoadBalancer) for bare-metal clusters. The implementations of network load balancers that Kubernetes does ship with are all glue code that calls out to various IaaS platforms (GCP, AWS, Azure…). If you’re not running on a supported IaaS platform (GCP, AWS, Azure…), LoadBalancers will remain in the “pending” state indefinitely when created.
Bare-metal cluster operators are left with two lesser tools to bring user traffic into their clusters, “NodePort” and “externalIPs” services. Both of these options have significant downsides for production use, which makes bare-metal clusters second-class citizens in the Kubernetes ecosystem.
MetalLB aims to redress this imbalance by offering a network load balancer implementation that integrates with standard network equipment, so that external services on bare-metal clusters also “just work” as much as possible.
MetalLB runs in the cluster, and just like longhorn, implements a part of the Kubernetes spec that is by default not implemented. MetalLB knows where workloads run, and it also knows how to tell that to your router. I chose to setup my MetalLB installation using BGP, which my Mikrotik router understands. the following MetalLB config configures a BGP connection, and allocates both an IPV4 and IPV6 pool for loadbalancers to use.
apiVersion: metallb.io/v1beta2
kind: BGPPeer
metadata:
name: peer
namespace: metallb-system
spec:
myASN: 64501
peerASN: 65530
peerAddress: 10.0.0.1
---
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: main-pool
namespace: metallb-system
spec:
addresses:
- 10.6.0.0-10.6.255.255
---
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: main-v6-pool
namespace: metallb-system
spec:
addresses:
- 2a10:3781:2235:a4::1-2a10:3781:2235:a8::1
---
apiVersion: metallb.io/v1beta1
kind: BGPAdvertisement
metadata:
name: advertisementto be the truth
namespace: metallb-system
spec:
ipAddressPools:
- main-pool
- main-v6-poolWhich then works with my router that is configured like:
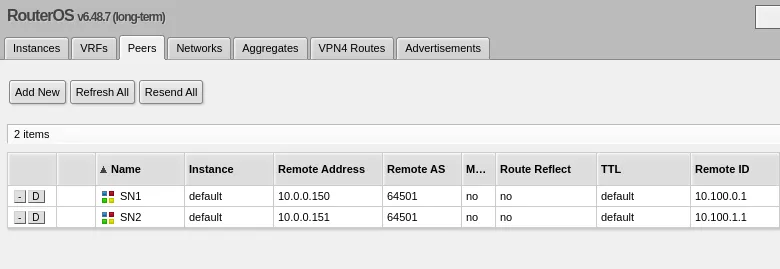
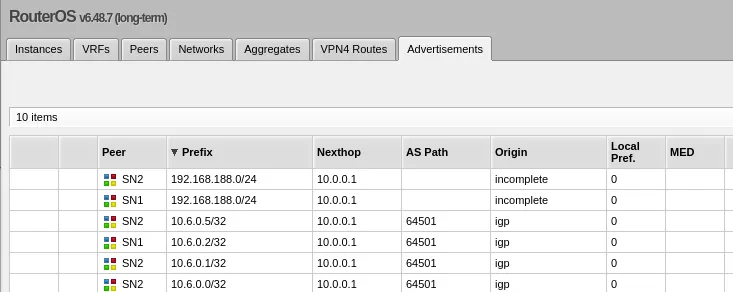
Final setup
After deploying Kubernetes to my servers, the setup looked like this:
It has many more features compared to my previous docker-swarm based setup, but it also required a ton more research to set it all up. If you require some of those features that docker-swarm is lacking, I highly recommend a similar setup. But if you are satisfied with docker-swarm, it is not worth the effort.
Both setups described above are incredibly stable, and have run for years, with >99.9% uptime. If you have any questions about my setup, or would like to see more detailled bare-metal Kubernetes examples, feel free to contact me.
The future
While my setup does everything that it needs to, it is still based on k3os. K3os has been deprecated some time ago. Luckily for me, all underlying software is still supported. However, this will not always be the case going forward. I have multiple options in the future
- ’Maintaining’ a private fork of K3os.
- Switching to an immutable OS like NixOS and adding k3s.
- Switching to a Kubernetes centered Linux OS such as Talos.
While options 1 sounds incredibly cool, would teach me a lot and offer seamless upgrade paths; I doubt that I have the time and knowledge to actually pull it off. It would be a colossal task. As for option 2 and 3, the jury is still out on that one. Please let me know if you happen to have experience with any of those options, or other k3os-migration related experience!
Other lessons that are important in specific situations
-
While Minikube is great for learning Kubernetes, it is NOT a good tool to test a setup created for bare-metal deployments before the entire cluster exists. Minikube by default implements loadbalancers, volumes, etc. If you expect those features to work out-of-the-box after using KubeADM, you will be sorely disappointed.
-
While Longhorn is great, it may occasionally happen that volumes get stuck after a sudden shutdown of a server node. I highly recommend enabling the
Auto Salvageoption which automatically promotes a volume in the case of a split-brain decision. -
While Helm is a great tool, I also feel like it has too much magic. I have no clear vision of what my cluster is doing when I am using external helm charts (which I find borderline unreadable). So I tend to avoid Helm, and strongly prefer Kustomize. I have written my own Kustomize definitions for apps with highly complex helm charts (eg. Gitlab).
-
While the Kubernetes documentation is insanely good, the documentation of other tools might not be. If you ever feel uncertain about the configuration of a tool, feel free to use tools like sourcegraph to search public git-repositories for similar configurations.
If you spot any mistakes or if you would like to contact me, visit the contact page for more details.